Here at iMotions, we specialize in data – the easy collection and analysis of biosensor data for human behavior research. One of the topics that we regularly hear a lot of interest about is the use of biosensor data to explore the creation of predictive models for human behavior.
Predictive models are the bedrock of artificial intelligence (AI). Often based on machine learning methods (which we will explain in more detail below), they involve using patterns in data to make predictions about what future data will look like. This allows a machine to make predictions about the world – to have artificial intelligence.
These models can have implications for many industries, from predicting the success of an online marketing campaign, to creating emotional algorithms for the next generation of human-centric vehicles. In an age where “data is the new oil”, the information coming from biosensors holds deep promise for those who know how to use it.
This article will explore how the evolution of more human-centric AI can be fueled by biosensor data. But to get there, we first need to understand what’s happening with the data.
Machine Learning
Data scientists use many different kinds of machine learning algorithms to extract insights and patterns from data, but in general, these algorithms can be divided into two categories: supervised and unsupervised learning.
Supervised learning can best be likened to a “tutor” (the data scientist) using a set of correct samples, or training data, to teach a “student” (the algorithm) a particular set of associations.
For example, the tutor could provide photos of animals, correctly labeled, and some defining characteristics like whether the animal has spots, stripes, and/or wings. After learning the information, if we give the student a novel animal photo, it should be able to guess what animal it is, depending on the information it’s already been trained on. Some examples of supervised learning algorithms include regressions and support vector machines.
Unsupervised learning, on the other hand, does not have this tutor-student relationship. In this scenario, the algorithm is given a set of data with no answers, and has to look for defining patterns on its own.
So for this example, the student is given a set of animal photos with labels, and without help, the student finds its own similarities or classifiers that we might not have thought of previously – spots and stripes could definitely work, but the animals could also be classified by color, or the number of legs, or whether it’s land or sea-dwelling (what a smart algorithm!). The algorithm can then use the rules it’s established in order to make guesses when it’s presented with novel pictures. Some examples of unsupervised learning algorithms include k-means clustering and principal component analysis.
Machine Learning
Data Mining
Algorithm
Classification
Neural Networks
Deep Learning
AI
Autonomous
Applying these algorithms to something as complex as human behavior and emotions may seem like a daunting task. However, the advantages are obvious: machine learning allows you to detect and use patterns in massive datasets that incorporate multiple variables and dimensions – something our own brains can only handle so much of.
Biosensors are particularly capable of producing huge datasets – the patterns within them hold great promise for helping understand human behavior.
But how exactly can biosensors help address some of the challenges in human behavior research? We’ll go through two examples below.
Characterizing Human Behavior
Human emotions and behavior can range from simple to complex. While the characterization of complex facets of human behavior is a non-trivial task, biosensors and machine learning can help enormously. Consider the use of biosensors in advertising:
Simple question: Does someone notice my company’s brand in a commercial? Potential solution: eye tracking.
Moderately difficult question: How engaging is my commercial to viewers? Potential solution: eye tracking, facial expression analysis, electrodermal activity (EDA).
Complex question: How does my company’s brand identity and loyalty play into a viewer’s experience when watching my commercial? Potential solution: eye tracking, facial expression analysis, EDA, EEG, self-report, implicit association testing.
The general rule is that the more complex and abstract the behavior, the more biosensors (and the more sources of data) you should have. However, this makes the interpretation of that data increasingly difficult. This is where machine learning can come in.
One great example of a complex variable is mental workload, an important concept in human factors research (read more about mental workload and how to measure it here). In summary, there is no single operational definition of mental workload; the concept of workload is multidimensional and nuanced, involving an interaction between the objective nature of a task and the subjective experience of the human doing the task.
In addition, the measures used to define mental workload often differ depending on the nature of the task and which measures have been shown to be suitable through previous research. This makes the measurement of cognitive workload a particularly gnarly problem with biosensors. However, for these exact same reasons, cognitive workload is prime pickings for the use of machine learning algorithms. Unsupervised algorithms in particular have the highest likelihood of picking out patterns and associations in apparently disparate datasets. Thus, it is possible to create your own operational definition of mental workload, given the data that you have already collected for your specific use case.
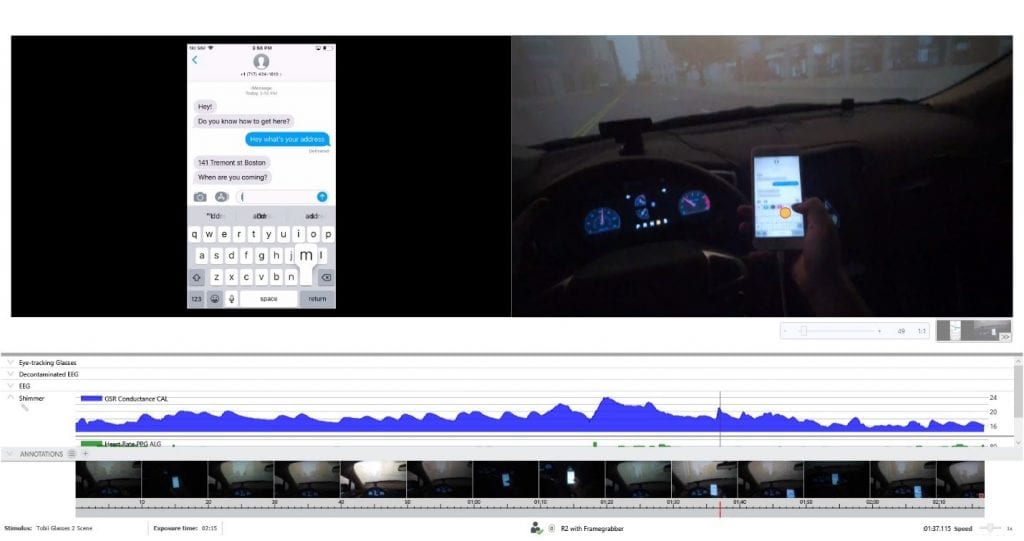
Ground Truth Data
Human brains are difficult to measure “in real life”. Behavior must often be used as a proxy for physiological processes. Fortunately, a common use of biosensor data is as “ground truth data”.
Ground truth data refers to data that indicates the actual facts of the matter. For humans, this could be whether or not someone is actually tired, anxious, or distracted (and so on), rather than simply what they say, which is prone to biases.
This is particularly well-suited for researchers who intend to use machine learning for modeling human behavior using indirect methods.
This is shown through the measurement of vigilance and drowsiness in the automotive industry. While original equipment manufacturers (OEMs) are interested in novel technologies for determining driver vigilance and drowsiness while driving, it is very difficult to have something like an EEG headset installed in a car cabin.
As an alternative, several manufacturers have tried analyzing driver vigilance based on behavioral measures from the vehicle itself. Sources of data could include weather conditions, the amount of time the driver has spent behind the wheel, and the position of the car within the lane.
None of these metrics are direct indicators of drowsiness. However, as the data is easily accessed and readily available, they are worth exploring as proxies for driver drowsiness if it means a possible reduction in the number of accidents on the road.

It is always good practice to validate these kinds of indirect behavioral models against a “Ground Truth Variable” – for example a definitive and physiological measure of drowsiness. In this way, we can ensure that the model is truly representative of the driver’s mental state and that its assessments of drowsiness are accurate.
There are many biosensors out there that can characterize drowsiness as ground truth data. Electrodermal activity (EDA) and heart rate can be used to reflect physiological arousal, facial expression analysis can provide measures of eye closure, and electroencephalography can be used to quantify the dominance of theta and delta waves in an EEG power spectrum that are associated with drowsiness and sleep. Using biosensors to validate algorithms gives more confidence in the accuracy of the model, and provides more scientific credibility too.
Download iMotions
VR Eye Tracking Brochure
iMotions is the world’s leading biosensor platform. Learn more about how VR Eye Tracking can help you with your human behavior research.